Some quick notes from a great discussion/breakfast put on by Canvas Ventures and Bloomberg Beta focused on building AI products in the real world.
Pipeline Strategies
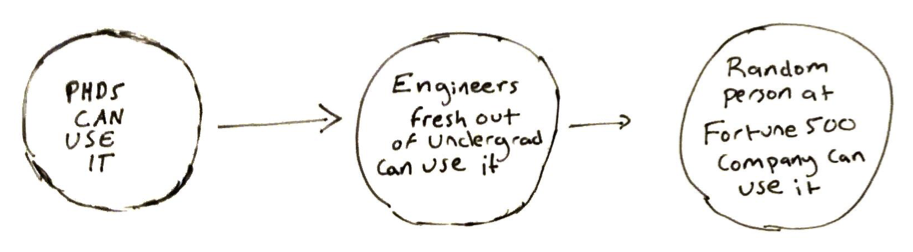 One strategy for developing AI products is to start with a full product that is only usable by the PhDs who built. Then, you develop it further so that an engineer straight out of undergrad can use it. Finally, you refine it to the point where a random person at a Fortune 500 company can use it.
One strategy for developing AI products is to start with a full product that is only usable by the PhDs who built. Then, you develop it further so that an engineer straight out of undergrad can use it. Finally, you refine it to the point where a random person at a Fortune 500 company can use it.
Always assume that your end users have no idea what’s going on under the hood.
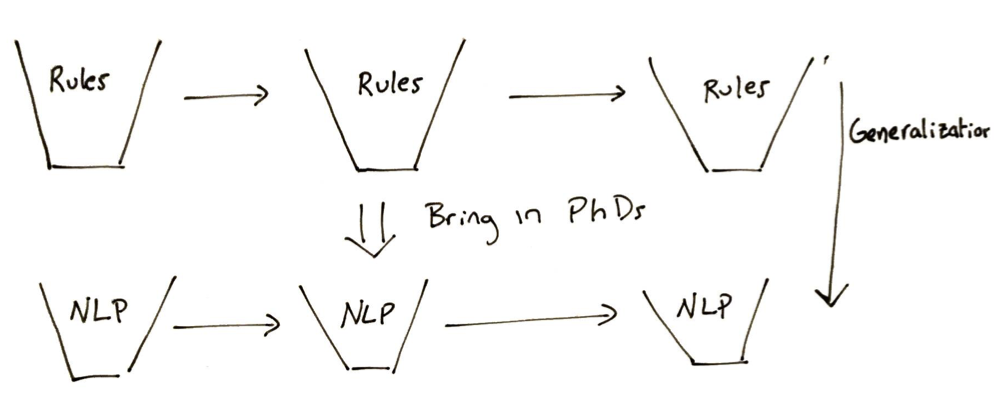
Another strategy for developing AI products is to have hardcore developers - not PhDs develop a pipeline of rule-based buckets. This is fragile, but each peace can be tested individually. Then you bring in PhDs who generalize each bucket with NLP and other machine learning techniques. This method allows you to ensure that your key use cases are always addressed before worrying about the AI.
Team Composition and Communication
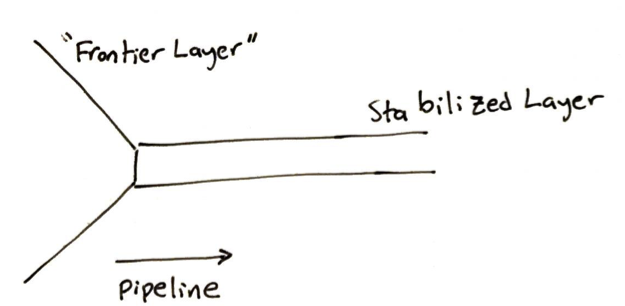
A data scientist/research engineer + prototyping systems engineer is a formidable team. Together, they can stabalize “frontier layers. Meanwhile, the pure researchers are creating the frontier layers ~6-12 months ahead of the rest of the company.
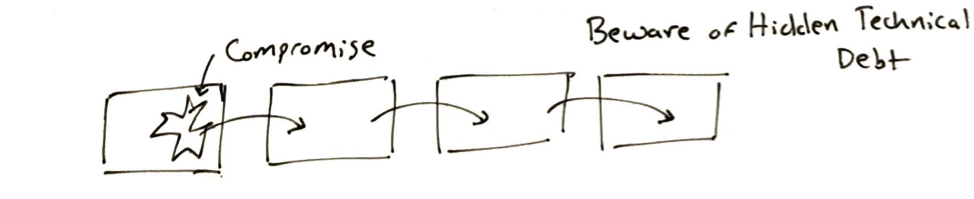
ML pipelines can become so long that pieces farther down the pipeline are shaped around technical debt earlier in the pipeline. Beware!
PMs can be a critical bridge between customers and those building the AI product. Their (very hard) job is to transform fuzzy problems into concrete numbers.
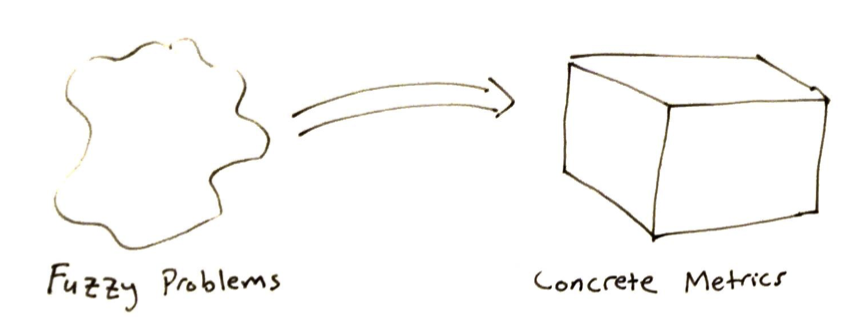
How do you get metrics on fuzzy problems? Remember, people are terrible at coming up with number-based metrics, but are amazing at discriminating between two possibilies - Good/Bad, In/Out, A/B. If you can pose a problem in that way, you can get the metrics you need.
Building Trust
Certainty about undercertainty is a big and often ignored consideration. You would hope that when an AI system says it’s 99% certain its answer is correct, you would also be 99% certain its answer is correct. This is rarely the case and instead you have systems that are usually correct at 50% certainty and incorrect most of the time at 99%. One possible step towards addressing this is Yarin Gal’s Baysean Model.
Failing intelligently is another huge piece that people often gloss over. Failing intelligently is what you expect a real person to do - “I’m sorry, I don’t know about that - I think it might be like this other thing I do know, or I can refer you to someone who does.” That example contrasts to many systems who’s failure modes look like “Siri, what is the definition of failure” “Ok. Calling your mother!”
A brilliant and extreme strategy to building intelligently failing system is to start with a system that literally doesn’t work but still provokes positive reaction. From there, everything that does work is all upside.
Some open questions:
- Where does design iteration sit in the pipeline? It’s easy to set metrics for tasks with clear success (getting the right answer, destroying weeds) but for anything else they will need to evolve over time.
- What are amazing ways to fail intelligently? There might be rich material here.
If you enjoyed this post, please share!